Update 2021-02-24: The Chrome developers have rolled back the change.
The latest stable Chrome (released February 4), breaks the way keywords can be used to invoke search engines from the omnibox (address bar). TLDR: typing space after the keyword no longer works, but tab does. Disabling the omnibox-keyword-search-button flag will revert to the old behaviour.
Prior to the upgrade I could type g foo directly in the omnibox, hit enter, and get Google search results for “foo”. After typing the space after the “g”, the keyword gets expanded to “Search Google” or similar, so in the case of “g foo”, you actually see something like “Search Google | foo”.
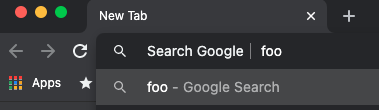
This works because I configured Google search to use the “g” keyword, from the chrome://settings/searchEngines settings page, as documented by Google.

However, this stopped working in Chrome 88.0.4324.150. Instead of “g foo” invoking the search engine I’d configured with keyword “g”, it invoked the default search engine with the query “g foo”! This was extremely disconcerting since I’m very accustomed to using keyword prefixes to search different websites.
However, you can still get at the keyword search functionality by hitting tab after the keyword rather than space. So in the previous example, typing gtabfoo will search for “foo”. The tab key doesn’t work quite the same way that space used to: it moves focus to a button in the autocomplete list for the keyword search, but merely having focus is enough to activate the search when you continue typing.
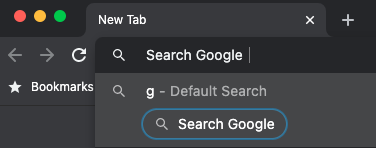
The Chrome search engine shortcuts no longer auto-fill with space bug on the Chromium tracker explains that this is due to the new button, and that you can get space working again by opening the chrome://flags/#omnibox-keyword-search-button settings and disabling the omnibox-keyword-search-button flag.
